Hello, I got a 20 nodes cluster before, which has reached 50% disk usage, so I add 9 new empty nodes to the cluster. But then the problems occured. The cluster has been turned into migration status for 2 weeks, and are still migrating. Here is the info for the cluster:
The aerospike server version is 3.8.3, all the config of the nodes are the same, the machines are also the same.
Actually I got another cluster in another DC, which is a mutual backup to this cluster. I add the same number new nodes to that cluster either, and that cluster has finished migration in one week, and became balanced status. But this cluster seens far away from balanced status.
So I want to know what happened to this cluster? How can I fix the problem?
The first arrow points to the stats of backup cluster as I mentioned above. When I add 5 new nodes to the backup cluster. The second arrow is when I add another 4 new nodes to the cluster. After the two operations, “Objects to be transmited” both grew and then dropped very fast.
The third arrow points to the cluster that I ask questions for, when I add 9 new nodes at one time. The “Objects to be transmited” grew up and dropped very slow, quite different from the backup cluster. And actually the backup cluster has higher load than this cluster.
Is it because I add 9 new nodes at one time? But I don’t see a limitation about the number of new nodes in the documents.
I don’t know how the monitor computes the “Objects to be transmitted”, The monitor is buildt by my former colleague, using a open source component call “Grafana”.
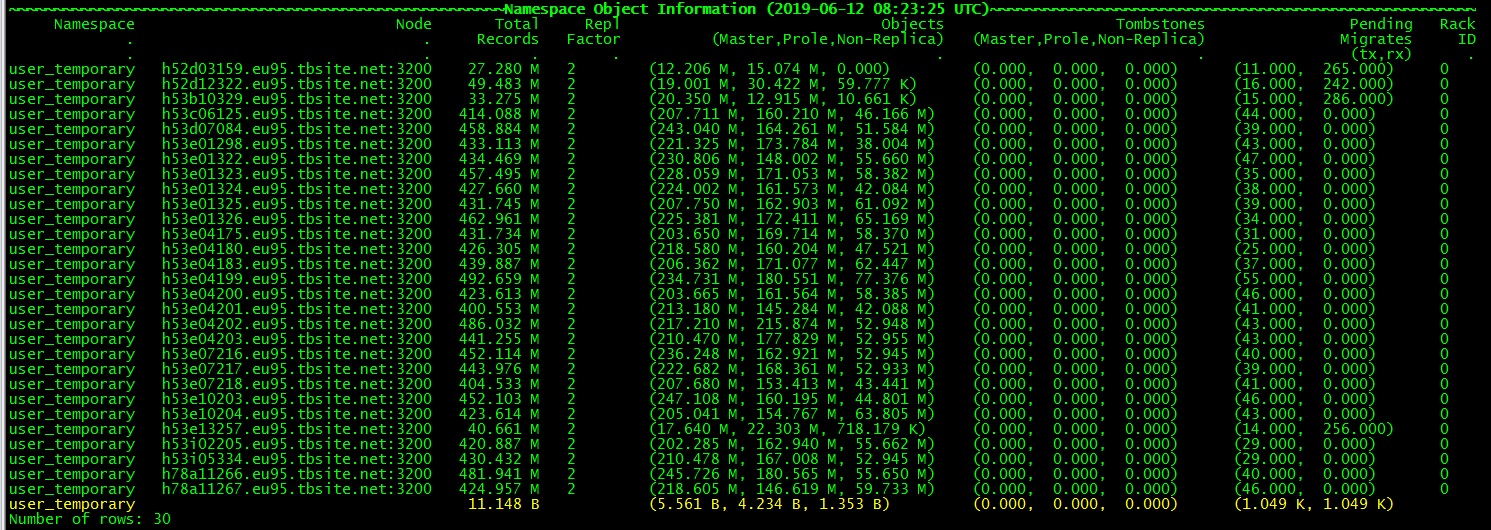
I’ve read the basic priciples about aerospike, the documents say that one namespace is mapped into 4096 partitions. However this seens not correct according to the stats.
There is only one namespace in this cluster, the “show statistics like migrate” command shows that the sum of “migrate_partitions_remaining” of each node is much more than 4096. Is there anything I misunderstand?
The tx/rx number is also confusing. The 9 new nodes have an average tx of 130, an average rx of 1.4K. The new nodes are added at the same time. As I comprehended, the new nodes should have a big num of rx, but the tx should be 0. Why would the cluster transmits data from old nodes to new nodes, and then transmits data from new node again?
And to some old nodes, their disk usage have pass 50%, why would they have a higher rx num than tx num? I really can’t figure out how the auto-balancing works.
There are only 4096 partitions, but there can be more than 4096 migrations. Worst case for replication-factor=2 is 4096 * N_nodes if you consider the case of recovery from an N way network split.
The new protocol in 3.13+ behaves closer to what you describe. The older protocol advanced a returning/eventual master to master right away. The new algorithm tries to choose a node that will generate less duplicate resolution traffic (basically the node that was master continues as acting master until the returning/eventual master fills.
Adding one node would behave as you describe in the new protocol, but when you add more then 1 (which is totally ok in the new protocol but potentially unsafe in the older version you are running) the eventual master fills first and then it replicates to the new replicas (so it will have tx for where it is eventual master and rx where it is taking over a replica position).
In the Enterprise 4.x we have a feature called “uniform-balance” that evenly distributes partitions to all nodes. The default balance randomly distributes partitions and you can get unlucky.
I have observed for one more day, and I find the “Pending Migrates” number rolls over and over again. It changes in a range of 22K to 19K, but never reduce lower than 19K.
The first screenshot took at last day, shows that the tx/rx number is 21.221K, here is the screenshot I just took, the tx/rx number increased.
I think adding 9 new nodes at same time may trigger some bugs, makes the cluster successively calculates the distribution of partitions, and in each period, the cluster gets a different distribution result, and adjust the migrate plan again and again, which makes the tx/rx number can’t reduces to 0.
Here is another cluster with 25 nodes originally, and then I add 4 new nodes to the cluster at the same time, the migration works perfectly, the 4 new nodes have a high rx number, the other old nodes have only tx number, none rx.
This is what I expect, there are only data move out from old nodes. I’m not sure about the details of “random distribution” as you mentioned, but this cluster works like it’s using consistent-hashing to calculate the partition distribution, thus data only transmit from old nodes to new nodes.
Back to the question, I will observe for another day. But I’m afraid that the tx/rx num would still stay higher than 19K. So is there any way to make the migration become stable? Or can it be stopped?
Oh, I’ve found a problem, the log shows that the number of nodes keep changing.
Jun 11 2019 00:37:10 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 00:37:22 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 01:11:14 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 01:11:31 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 05:53:46 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 05:53:55 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 06:07:27 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 06:07:31 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 06:21:20 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 06:21:26 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 06:51:20 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 06:51:31 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 08:49:14 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 08:49:20 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 08:49:30 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 08:49:46 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 12:23:47 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 12:24:15 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 13:42:30 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 13:42:44 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 14:19:06 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 14:19:24 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 19:17:02 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 19:17:12 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 19:46:25 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 19:46:30 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 19:55:58 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 19:56:11 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 22:19:57 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 22:20:26 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 23:04:19 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 23:04:25 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
Jun 11 2019 23:04:47 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 28
Jun 11 2019 23:04:52 GMT+0800: INFO (clustering): (clustering.c:5807) applied cluster size 29
So this should be the cause of successively migrating. But the log doesn’t show which node is lost or which node is newly added. I would try to locate that problematic node.
It does use a deterministically random distribution. This is done by hashing each node_id with the partition_id, sorts hashs to determine the node sequence for a particular partition.
The problem node will likely report 1. You can also put the paxos logging context into detail mode which may tell which node_id is leaving (the newer versions will since 3.13, don’t remember if older versions also reported this).
Wait, clustering.c didn’t exist in 3.8.3, you must have upgraded to 3.13+. So instead of paxos, you will want to set clustering to detail to see which node_id is having problems.
Also what are your heartbeat settings and have they been configured the same on all node?
Yes, my mistakes not to check the cluster version. I’ve several clusters, some of them are version 3.8.3, but this one and its backup cluster is “Aerospike Community Edition build 3.16.0.1”.
The heartbeat setting is
mode mesh
interval 250
timeout 40
each node has same config.
I have set the clustering log level to detail, and wait for the lost node occurred.
Those setting are really high. This means it takes ~10 seconds for the cluster to respond to a disruption - so if a node were to suddenly drop from the cluster (maintenance or otherwise) there will be a ~10 second window where writes that would have gone to this node will fail. Typically the interval is set to 150 and timeout is 10 which gives a 1.5 second window - often in cloud environments timeout is increased to 20. I can only assume your predecessor was experiencing problems with the default heartbeat configuration and increased it - the problem your predecessor was experiencing may be related to the node you are currently tracking down.
edit: meant ~10 seconds, previously I wronte 20 seconds.
The problem is more severe. I thought the cluster lost a certain node, but actually it’s losing random nodes.
The log shows that each time the cluster lost a different node.
The adding new node operation may lead to a vicious circle. When adding new nodes, the load of the cluster increase, and some nodes become unavailable for a short time, which will trigger the “node depart” event, thus the cluster rearranges the migration plan. However, more migration tasks would lead to higher load, and then nodes might become unavailable more frequently, and then get into a vicious circle.
The essence of the problem should be that the cluster has originally reached a critical load, that’s why I wanted to add new nodes to it, and then triggered the problem.
I have adjusted the timeout param to an even bigger number, which makes the cluster will no more loses nodes. This could cause data write error, but breaking the vicious circle is more important.
After I adjusted the timeout param, the monitor shows that “Object to be transmitted” stop increasing, and become decreasing.
Just from the symptoms, I think you have an issue with your network or network interface card settings and you are trying to compensate it by adjusting Aerospike configuration to sub-optimal.
According to the documents, this stat means objects beyond master and replica, only exists during migrations. Thus in a sense it could be equivalent of objects to be transmitted, or objects being transmitting.
I’m still trying to locate the problem. The system monitors of a single node show that when in the non-response period, the node has a peak disk read, its load-1-min rose over 65, whereas it only has 64 cpu cores, which means the node was fully working at that moment, and that could cause no response to the heartbeats.
In the recent 2 days, this cluster is still migrating, the monitors show that the machine has intermittent peak of disk read, which makes the load usage rises over 100%.
I’m not sure why the default config of migration could cause such high disk read, but if it does, aerospike might need an optimization for migration.