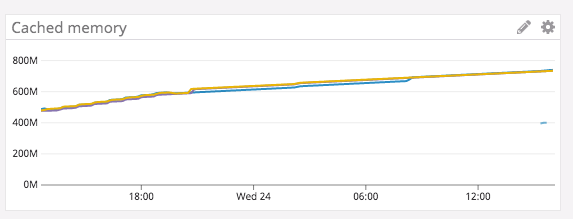
I’m using aerospike build 4.5.2.1 running on Debian 9 VMs. Every record being written contains the following bins:
PK: string (always < 256 bytes)
Blob: byte array (2-4 MB)
ContentType: string (< 16 bytes)
I’m storing each record in 2 separate namespaces with different ttl (segments-disk stored on SSD with a 3 hour ttl and segments-memory stored in RAM with a 3 min ttl). This is configured as a 3 node cluster running on GCE VMs. There is a constant network ingress of 22 MBps and 16 writes per second to segments-memory, and all objects in memory are being stored with a 3 min ttl (configured in the application). As expected, I see the number of objects stay constant around 2900 (16 writes/sec * 180 sec) after the first 3 minutes of running. I configured nsup to run every 30 seconds to reclaim memory faster.
However, I am observing a slow but constant increase in memory usage of about 1.3 kB/s even though the number of keys and rate of ingest are not changing.
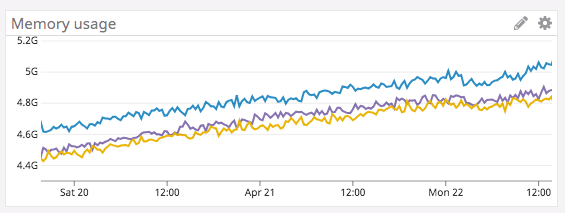
It looks like about 80 bytes of memory is leaking per write to the segments-memory namespace. While this smells like a memory leak, I’m not sure if there is something in my configuration that is causing memory to not be freed up. Any help on this would be greatly appreciated. Pasting my aerospike.conf below.
# Aerospike database configuration file.
# This stanza must come first.
service {
user root
group root
paxos-single-replica-limit 1 # Number of nodes where the replica count is automatically reduced to 1.
pidfile /var/run/aerospike/asd.pid
proto-fd-max 15000
}
logging {
# Log file must be an absolute path.
file /var/log/aerospike/aerospike.log {
context any info
}
# Send log messages to stdout
console {
context any info
}
}
network {
service {
address any
port 3000
}
heartbeat {
mode mesh
port 3002
# use asinfo -v 'tip:host=<ADDR>;port=3002' to inform cluster of
# other mesh nodes
mesh-seed-address-port aerospike-server-v7-1 3002
mesh-seed-address-port aerospike-server-v7-2 3002
mesh-seed-address-port aerospike-server-v7-3 3002
interval 250 # milliseconds between successive heartbeats
timeout 20 # number of missing heartbeats after which node is declared dead
}
fabric {
address any
port 3001 # Intra-cluster communication port (migrates, replication, etc)
}
}
namespace segments-memory {
replication-factor 1
memory-size 6G # assuming 7.5G VM, increase if using a bigger VM
default-ttl 1d # upper bound of in-memory storage. Note: application should set a lower ttl to prevent OOM
conflict-resolution-policy last-update-time
storage-engine memory
nsup-period 30
}
namespace segments-disk {
replication-factor 2
memory-size 1G # assuming 7.5G VM, increase if using a bigger VM
default-ttl 5d # default ttl 5 days. Note: application should customize this and not rely on default value
conflict-resolution-policy last-update-time
# storage-engine memory
# To use in-memory storage, comment out the lines below and uncomment the line above
storage-engine device {
device /dev/sdb # ssd path
scheduler-mode noop # This line optimizes for SSD
write-block-size 8M # this limits the maximum size of a record. recommended value for ssd is 128K but that
# means we cannot store objects bigger than 128 KB
data-in-memory false # Store data in memory in addition to file.
}
}
Another thing I noticed was that the memory usage reported by AMC for both the namespaces combined is significantly lower than what is reported by top. AMC reports about 25% memory in use whereas top reports asd consuming about 47% memory. Is this expected?